在 Meissa-Qwen2.5-7B 的基础上, 我微调了 Qwen2.5-14B. 本次微调依然分为两个部分: 破限和 rp 增强
Qwen2.5-14B-Instruct-Uncensored
在给 7B 版本破限时, 我注意到, Qwen 的审核在某种程度上和 prompt 模板绑定在了一起. 然而我目前还没有能力直接更换模板训练, 所以我的方案是更换 Qwen 原本的提示词, 并将破限语料和新的提示词绑定在一起
基于这个想法, 我构建了 meissa-unalignment 数据集, 将所有的 system prompt 统一替换成了:
| |
然后使用 SFT 训练出了 Qwen2.5-14B-Instruct-Uncensored
模型使用 FSDP+4bit-QLoRA 训练, 训练超参数如下:
| |
进行破限训练花费了我超过 100 个 GPU 小时. 以下是 train loss 和 eval loss 记录:
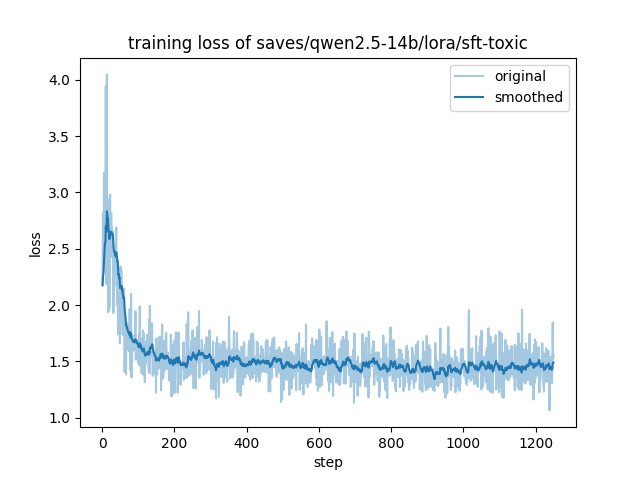
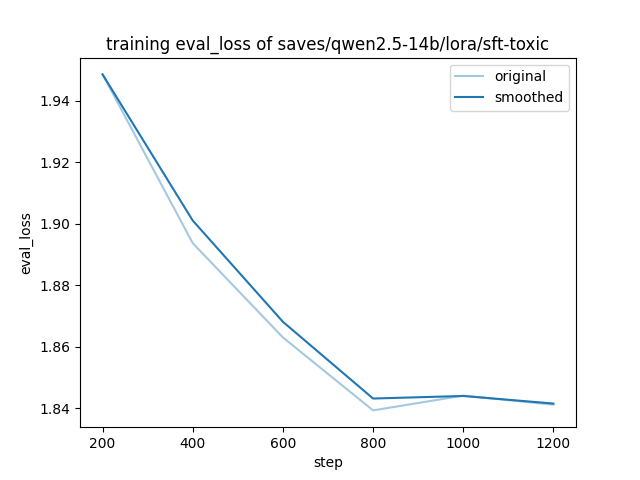
可以注意到, train loss 明显低于 eval loss, 说明在训练过程中可能出现了 overfit, 但我的本意就是想把破限语料和系统提示词绑定在一起, 即 overfit 到 system prompt 上, 所以这是合理的
Meissa-Qwen2.5-14B-Instruct
这次的 Meissa-Qwen2.5-14B-Instruct, 我大幅精简了使用的数据集, 仅使用了:
训练了 2 个 epoch 得到. 超参数配置同上. 仅花费了 300 个迭代步数, 得到 train loss 如下:
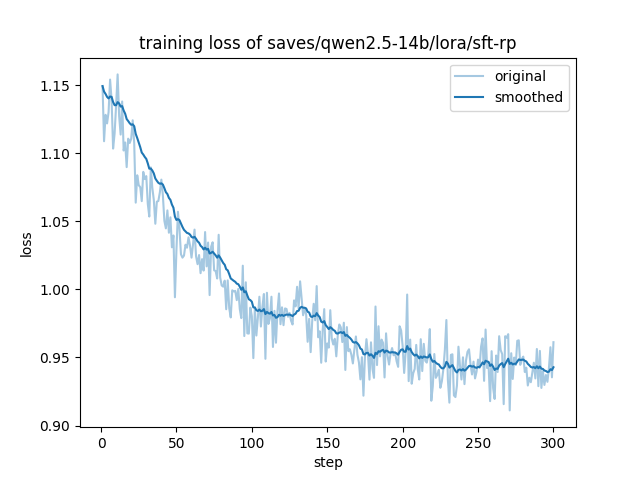
由于迭代步数过少, 没有 eval loss 图片