这里有一个相关的系统架构图供参考:
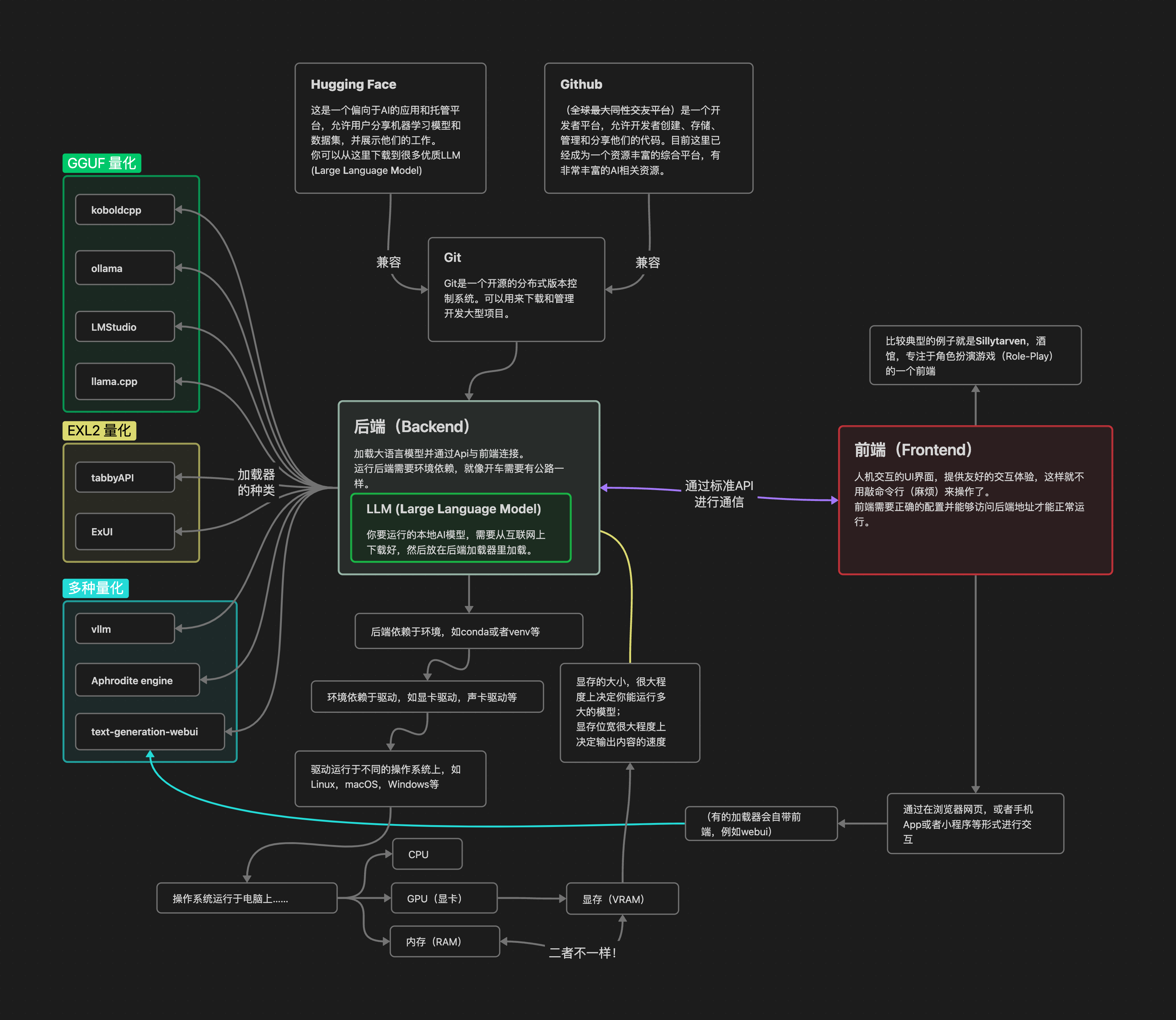
另附有常见问题速查, 见本文最末尾, 如果你是新手, 建议详细阅读本文后再看
写在前面
首先需要声明的是, 自己动手玩大模型是有技术门槛的, 是需要你动一点脑子去学习的. 如果你不愿意动脑子, 只想衣来伸手饭来张口, 或者遇到一点问题就一股脑地问人, 又或者你连阅读一篇简体中文编写的新手入门教程的耐心都没有, 那么我不建议你尝试自己部署大模型. 你可以使用别的公司包装好的大模型应用, 这样一站式的解决方案非常方便, 但代价就是可玩性远远不如自己动手, 并且有诸多限制
这是一篇面向小白的科普入门教程, 用于快速给小白讲述玩大模型需要掌握的一些基础知识. 阅读这篇教程, 你会:
- 了解遇到问题时应该如何处理, 如何有效的寻求帮助
- 了解大模型和一些计算机相关的常识
- 了解不同的操作系统的特点, 以及如何选择
- 了解一些基础的电脑操作
- 了解不同的量化模型, 以及如何选择
- 了解不同的模型加载器, 以及如何选择
但是, 这篇教程不会讨论:
- 如何设置 SillyTavern
- 如何给模型破限/破甲
- 如何设计采样器参数
- 如何设置优化 prompt 模板
- 如何选择你想要的模型
- 如何寻找角色卡并导入到 st 中
- 如何微调模型
是萌新没关系, 人非生而知之者, 所有人都是从小白开始的. 重要的是你有一颗谦虚的心, 愿意积极地学习新事物, 愿意主动地搜索来解决自己的问题; 而不是当一个"爷新"
一键包
请立刻删除你电脑中的任何一键包, 哪怕这是群主的视频里分享的. 因为一键包不仅老旧, 更新不积极, 而且其中的各个组件互相耦合, 难以更新升级. 且使用一键包会让你丧失自己部署大模型的能力, 逐渐成为没有一键包就不会玩大模型的笨蛋
提问礼仪
- 当你遇到问题时, 请优先上网搜索. 一般地, 你可以复制一小段关键的报错信息, 然后粘贴到Google搜索中进行搜索. 注意, 请务必使用Google, 百度或必应只会给你推送广告和垃圾信息
- 你还可以在群里搜索关键字, 也可以找到前人问过的和你相关的问题
- 当且仅当以上两条你都尝试过且无法解决你的问题时, 你可以在相关论坛中发送求助请求, 但请注意遵守论坛的相关规则
当你在论坛中求助时, 请确保你的消息中包含如下要点:
- 系统信息: 你在用什么系统? Arch Linux? Windows11? Windows10?
- 环境信息: 你用的是什么加载器? koboldcpp? webui? tabby? vllm? 还是其他的东西?
- 模型信息: 你用的是什么模型? 请把模型名和量化方式一并给出, 例如 Qwen2.5-32B-Instruct-Q5_K_M, Mistral-Nemo-Instruct-4.65bpw-exl2 等
- 模型信息补充: 如果你的问题是关于模型生成的文字方面的, 那么你还应该提供你使用的 prompt 设置, 采样器设置等信息
- 你做了什么: 你是如何一步一步遭遇这个问题的?
- 简要描述: 简要描述你遇到了什么问题
- 报错信息: 最好是在命令行中复制报错信息, 然后粘贴到你的帖子里发送出来. 如果你不会, 那么就使用屏幕截图, 但一定要把终端信息截全
对于 Windows 下, 点击某个可执行文件而没有任何命令行输出的情况, 请在那个文件所在的目录下打开命令行, 然后在命令行中输入
./那个可执行文件名.exe并运行, 从而观察是否有信息输出 注意, 请将上文中的"那个可执行文件名"替换成你实际的文件名, 不要直接复制命令运行
直接丢一张没头没尾的截图, 然后问"大佬们能不能帮我看看这是什么问题啊", 是不礼貌的提问行为. 不是所有人都愿意和你玩猜谜游戏. 关于如何提问, 请参考这个GitHub项目: 提问的智慧
预备知识
大模型相关
- llm, 模型, ai: 一种神奇的东西, 你给它发送文字, 它能相应地生成出一些文字给你
- 加载器, 后端, loader, backend: 能够加载模型, 并且提供API供别人或者别的前端使用的东西. 你可以把模型想象成货物, 加载器就是装货物的车
- API: 加载器提供的一种标准接口,就像接头的暗号一样,是前后端之间相互联系的一种方式. 有了这个东西, 你, 或者前端就不用管加载器里面是怎么运行的, 只要按照API提供的使用方式使用就行了
- 并发: 指的是多个事情, 在同一时间段内同时发生了. 这里特指加载器在同一时间收到多个AI生成文字的请求
- 前端, frontend: 在后端的支持下, 能玩各种花活的东西, 例如后文要讲述的**SillyTavern(酒馆)**就是一个典型的前端,前端可以简化交互, 优化体验
- 量化: 原本形态的大模型太大了, 以至于你有限的显存难以容纳下去. 量化是这样一种手段, 可以大幅减小模型的体积, 显著加快模型运行速度, 并且稍微降低模型的性能表现. 换言之, 你有限的显存空间可以放下更大的模型的量化版本了
- 甲, 审核, 对齐, 道德对齐: 和b站的审核差不多, 模型厂们都会千方百计地给自己的模型加上一些限制
- 提示词, prompt: 简而言之, 就是给模型输入的文字. 模型会根据你的提示词生成一些文字. 通过精心设计提示词, 可以让模型生成出一些你想要的东西. 想进一步了解可以参考: Prompt Engineering Guide
- 采样器: 采样器是模型运行的关键环节, 它决定了模型的输出结果. 采样器的设置可以影响模型的输出结果, 因此, 你需要对采样器进行优化, 才能让模型生成出更符合你的要求的文字
- 破甲, 破限: 顾名思义, 即通过精心设计提示词等方式, 破除模型厂给模型的各种限制, 从而可以做一些本来不能做的事情
- hf, HF: huggingface网站的简称, 你可以在这个上面浏览和下载各种不同的模型
计算机常识
- Git: 代码管理工具, 你可以用这个在GitHub上下载很多好玩的代码仓库到你的本地, 然后运行起来. 后文要讲述的很多后端和前端, 例如llama.cpp, tabbyAPI, SillyTavern等, 都需要(推荐使用)用到Git来下载
- GitHub:是一个开发者平台,允许开发者创建、存储、管理和分享他们的代码. 你可以在这里找到很多优秀的项目并使用git命令下载或克隆(clone)到你的计算机并运行
- 克隆, clone: Git提供的一个命令, 通过这个命令你可以将GitHub上的仓库下载到本地
- 命令, 运行: 在本文中, 命令这个词 尤指 你打开命令行界面, 例如Windows下的powershell或者CMD, Linux或MacOS下的终端, 然后输入一些命令来运行. 注意, 本教程中所有的命令或者运行都是在命令行中进行操作, 而不是让你点击鼠标运行一些东西
- 虚拟环境: 很多时候, 不同的代码仓库需要不同的Python模块, 而这些模块之间很可能会起冲突. 这时候就需要虚拟环境派上用场了. 有了虚拟环境, 只需要将不同的代码仓库放到不同的虚拟环境中, 当使用某个仓库时就激活这个虚拟环境, 妈妈再也不用担心依赖打架了
- 路径, 目录: 是你存放下载下来的模型仓库的地方. 你必须先进入到相应的目录, 才能运行仓库中的代码, 或者是激活虚拟环境, 或者是安装Python模块. 就好比你把一包纸放在厕所里, 那你就必须进入厕所才能拿到这包纸, 你不能在厨房里拿到这包纸. 有的时候需要注意区分相对路径和绝对路径
热身训练
安装显卡驱动
想要使用你的独立显卡, 安装驱动是必不可少的. 如果你和我一样使用 Arch Linux, 那么仅需一行命令即可安装驱动:
- N卡用户:
sudo pacman -S cuda nvidia - A卡用户:
sudo pacman -S rocm-hip-sdk rocm-hip-runtime rocm-hip-libraries rocm-smi-lib
如果你使用 Windows, 那么你就只能先找到官网, 然后下载对应的驱动, 最后进行安装. 请查找您的显卡品牌并善用Google找到官方网站并查阅最新的官方文档一步一步跟随安装教程……
很麻烦, 不是吗
在安装完驱动后, 请务必重启电脑, 以使驱动生效
在终端/命令行中切换路径
想要在终端中切换路径, 只需要使用 cd 命令即可. 格式是:
| |
例如切换到 D:/models/tabbyAPI 就只需要在命令行中输入:
| |
注意, 在你运行仓库中的任何代码前, 请务必检查你是否在正确的目录下. 例如, 不要在 C:/Windows/System32 下运行本来应该在 D:/tabbyAPI 目录下的代码
命令行代理
你可以在浏览器中通过梯子访问外网, 但如果不经过配置, 你无法在命令行中通过梯子访问外网. 在 Windows 下, 不同的梯子提供的命令行访问方式不同, 你可以翻看你的梯子的使用说明, 或者询问你的梯子的客服. Linux 下, 只需要设置环境变量就好了
如果你没有命令行代理, 可能会出现安装st时没有动静的情况
从网上克隆代码仓库
请确保你可以使用命令行代理, 因为GitHub需要梯子
使用 Git 可以将网上的代码仓库下载到本地你指定的路径下. 格式是:
| |
注意, 在运行克隆命令前, 请确保你切换到了你想要的路径. 你可以在命令行中切换, 也可以在文件资源管理器中打开对应的路径, 然后在右键菜单中选择"在此处打开终端"
例如从Github上下载SillyTavern的代码仓库, 你可以运行以下命令:
| |
等待命令执行完成, 然后你会在当前文件夹下看到一个名为SillyTavern的文件夹. 恭喜你, 成功地从网上将一个代码仓库下载到了本地
从镜像站下载模型
如果你的梯子是有流量限制的, 那么直接从hf本站上下载模型可能会让你的流量捉襟见肘. 一个有效的解决方案是从hf-mirror上下载模型. 如何使用hf-mirror, 它的官网上已经给出了教程, 跟着它的做就是了. 我推荐的是它的方法二: huggingface-cli
如果你想在 Arch Linux 中安装 huggingface-cli, 你可以使用如下命令:
| |
这会在全局下安装 huggingface-cli. Linux 强烈不推荐在全局环境中使用 pip 安装任何依赖, 因为这很可能会污染你的环境, 把它变得一团糟. 想要使用 pip, 你应该先创建一个虚拟环境
在 Windows 下就没有这个限制, 你可以在全局环境中使用 pip. Windows 混乱的环境管理由此可见一斑
创建/激活虚拟环境
无论是 Linux 还是 Windows, 都可以使用 Python 内置的 venv 模块轻松地创建虚拟环境. 格式是:
| |
这会在你当前文件夹下生成一个 你想要的虚拟环境名 的文件夹, 这个文件夹中就是你刚刚创建的虚拟环境. 一个常见的虚拟环境名是 .venv
记得把"你想要的虚拟环境名"替换成真正的环境名, 比如
.venv,venv之类的, 不要复制了我的示例命令就直接粘贴到命令行里去了
想要激活这个虚拟环境, 在 Linux 下, 你需要运行:
| |
在 Windows 下, 你则需要在终端中运行:
| |
如果你是使用CMD, 则运行:
| |
注意: 在你激活虚拟环境前, 请务必确保你当前所在的目录下有这个虚拟环境文件夹!
连一个操作都要整出两种不同的命令出来, Windows 真的混乱不堪
想要退出虚拟环境, 只需要输入以下命令(通用):
| |
如果你喜欢让软件在电脑里拉史, 那么你也可以使用
anaconda或miniconda来创建和管理虚拟环境
认识量化
目前主流的量化方式有以下几种:
- GGUF
- EXL2
- GPTQ
- AWQ
量化是有不少优点的, 例如降低硬件性能要求等……量化通常会降低参数的精度, 量化的等级越高, 参数的位越少, 但一旦量化超过某个阈值, 这个阈值就像一个生死线, 量化超过这个生死线, 模型的能力会有非常严重的损失, 换言之, 变成智障.
一般地, 模型量化的生死线是 4 位量化, 对 GGUF, 是 Q4; 对 EXL2, 是 4bpw; 对 GPTQ, 是 INT4; 对 AWQ, AWQ 默认就是4位量化
在不同大小的模型的不同等级的量化之间比较的话, 优先选择大模型的低量化, 然后才选择小模型的高量化. 因为越大的模型越禁得起量化, 一般而言, 72B 4.65bpw 的性能是高于 32B 6.5bpw的
想要快速估计模型的占用, 你可以在hf上找到模型, 计算模型文件本体的总大小, 再加上大约2G的上下文空间. 讲这个大小和你的可用内存/显存进行比较, 就可以大致估计你能否成功加载这个模型
GGUF
当你满足以下任一条件时, 推荐你使用 GGUF 量化:
- 你是小白
- 你在使用 Windows, 且没有使用 WSL
- 你的显卡显存有限(例如只有8G), 但是内存相对宽裕(例如16G甚至32G)
- 你能忍受一秒钟蹦一个字的慢速(甚至可能更慢)
GGUF 量化可能是目前使用最广泛的量化, 从hf上浩如烟海的 GGUF 模型就能看出. GGUF 量化注重兼容性, 你可以使用显卡推理它(模型文件会加载进显存), 也可以使用CPU推理它(模型文件会加载进内存), 还可以同时使用显卡和CPU推理它
但是, 需要注意的是, 你在选择模型时, 要考虑模型文件的大小和你的内存大小和你的显存大小, 具体如下:
- 你能够把全部的模型都加载到显存中: 那么选择低于你显存容量的最大的模型就好了
- 你需要同时使用内存和显存来加载模型: 那么选择低于你内存容量的模型, 并且预留一些内存空间给你的系统. 给 Windows 系统预留的空间会更多, 谁让 Windows 这么臃肿呢
纠正一个误区: 当你同时使用内存和显存来加载模型时, 加载过程是先将模型全部加载到内存中, 然后再将一部分模型移动到显存中. 换言之, 你能加载多大的模型完全取决于你的内存大小, 而不是你的显存大小. 所以, 你需要根据你的内存大小来选择模型的大小, 而不是根据你的显存大小来选择模型的大小
层数: 模型是像千层饼一样分很多层的, 我们说同时使用内存和显存来加载模型时, 其实就是把模型的一些层移动到显存中, 让显卡来计算它们. 那么如何快速地估计你的显卡大约能容纳多少层, 从而减少试错次数呢?
你可以计算显存大小占模型总大小的比例, 来快速地估计应该放多少层到显存中, 具体公式如下:
$\text{放到显存中的层数} = \text{模型总层数} \times \text{显存大小} / \text{模型总大小}$
例如对一个80层, 总大小为40G的模型, 你想把它负载到一张显存大小为8G的显卡上, 那么你可以根据公式算出, 你的显卡大约能容纳 $80 \times 8 / 40 = 16$ 层, 你可以从16层开始尝试加载, 如果还是报错, 那就再慢慢降低层数直到成功加载
一般 GGUF 量化的模型在模型名中都包含 GGUF 关键字, 模型文件也是以 .gguf结尾. 一个典型的 GGUF 量化模型文件名长这样: qwen2.5-coder-7b-instruct-q4_k_m-00001-of-00002.gguf
相信细心的你已经注意到了, 这个模型是从 qwen2.5-coder-7b-instruct 这个原始模型量化来的, 下面我们来解析后面的参数的含义:
q4_k_m表明了量化的精度, 是Q4级别的量化, 数字越大, 量化等级越高, 模型大小越大, 模型性能损失越少, 反之亦然K是量化策略, 不用管它;M代表在同级别下的量化尺寸, 是Medium(中等), 相应地还有S, 代表Small(小的)00001-of-00002不是每个 GGUF 模型文件都含有这个部分. 这代表这的意思是这个模型被分成了两块, 这是第一块. 一般地, 你需要把模型的所有分块下载下来, 放在同一个目录下, 后面从加载器中加载模型时, 只要选中第一块模型即可.gguf后缀表明了这是一个 GGUF 量化模型
EXL2
当且仅当你满足以下所有条件时, 推荐你使用 EXL2 量化:
- 你不是小白
- 你显存充裕(至少16G以上)
- 你想要模型对你的文字做出快速响应
EXL2 量化是一种比较新的量化, 它能做到极限榨取模型的量化潜力, 提供面对单个请求时最快速的性能体验. 你仅能在显卡上加载 EXL2 模型, 你的模型容纳能力上限仅取决于你的显存大小
一般的 EXL2 量化的模型所有的模型文件应该存放在一个文件夹中. 一个hf上典型的 EXL2 量化模型的模型名长这样: Orion-zhen/Qwen2.5-32B-Instruct-6.5bpw-exl2
相信细心的你已经注意到了, 这个模型是 Orion-zhen 从 Qwen-2.5-32B-Instruct 原始模型量化来的, 下面我们来解析后面的参数的含义:
6.5bpw表明来量化的精度, 对应于 GGUF 的Q几. 数字越大, 量化等级越高, 模型大小越大, 模型性能损失越少, 反之亦然exl2后缀表明来这是一个 EXL2 量化模型
GPTQ
当且仅当你满足以下所有条件时, 推荐你使用 GPTQ 量化:
- 你不是小白
- 你有并发需求
- 你不想要 4 位的量化
GPTQ 是一种比较老的量化了, 作者更新也不怎么积极. 你仅能在显卡上加载 GPTQ 模型, 你的模型容纳能力上限仅取决于你的显存大小
一般的 GPTQ 量化的模型所有的模型文件应该存放在一个文件夹中. 一个hf上典型的 GPTQ 量化模型的模型名长这样: Qwen/Qwen2.5-32B-Instruct-GPTQ-Int8
和前文类似地, 你可以注意到, 这个模型是 Qwen 从 Qwen-2.5-32B-Instruct 原始模型量化来的, 下面我们来解析后面的参数的含义:
GPTQ表明采用的量化方式是 GPTQInt8表明这是 8 位的量化等级, 相应地还有Int4, 表明是 4 位的量化等级
AWQ
当且仅当你满足以下所有条件时, 推荐你使用 AWQ 量化:
- 你不是小白
- 你有高并发需求
- 你能接受 4 位量化
AWQ 量化是对 GPTQ 的优化, 在同样的量化精度下 AWQ 的模型性能更高, 多并发时的吞吐量更大, 但是应对单个请求时速度慢于 GPTQ. 你仅能在显卡上加载 AWQ 模型, 你的模型容纳能力上限仅取决于你的显存大小
一般的 AWQ 量化的模型所有的模型文件应该存放在一个文件夹中. 一个hf上典型的 AWQ 量化模型的模型名长这样: Qwen/Qwen2.5-32B-Instruct-AWQ
和前文类似地, 你可以注意到, 这个模型是 Qwen 从 Qwen-2.5-32B-Instruct 原始模型量化来的, 下面我们来解析后面的参数的含义:
AWQ表明采用的量化方式是 AWQ- 诶, 怎么没有量化等级啊? 因为 AWQ 只提供 4 位的量化等级
加载模型
注意: 所有的加载器对应一些兼容的量化方式. 不要强行让一个加载器加载它不支持的量化方式, 更不要把这样做后得到的报错信息拿到群里来问
目前主流的, 我用过的加载器按照支持的量化方式划分如下:
仅支持 GGUF 量化的:
仅支持 EXL2 量化的:
支持多种量化的:
- vllm: GPTQ, AWQ, BitsAndBytes, 等
- Aphrodite engine: 同vllm
- text-generation-webui: GGUF, EXL2, 原始模型, GPTQ, AWQ, BitsAndBytes, 等
接下来让我们逐个检查这些加载器的使用方法
koboldcpp
别称: kbd, kbdcpp, 狗头人
当你满足以下任一条件时, 推荐使用 koboldcpp:
- 你是小白
- 你在用 Windows, 且不想用 WSL
- 你不会/不想打开命令行输入哪怕一条命令, 只想用鼠标点击完成操作
如果koboldcpp较为复杂的配置界面让你有些无所适从, 不妨尝试LMStudio
首先前往koboldcpp发布页面, 找到最新的版本, 然后按照如下条件选择你要下载的版本:
- Windows, 没有独立显卡: 下载
koboldcpp_nocuda.exe - Windows, 有 NVIDIA 显卡, cuda 版本是 12.0 以上: 下载
koboldcpp_cu12.exe - Windows, 有 NVIDIA 显卡, 不知道自己的 cuda 版本: 下载
koboldcpp.exe - Windows, 有 AMD 显卡: 前往koboldcpp-rocm发布页面, 下载
koboldcpp_rocm.exe
当你完成下载后, 双击打开对应的.exe文件. 如果有杀毒软件阻止你运行, 选择仍要运行. 在等待一段时间后, 你应该能看到 koboldcpp 的窗口和一个命令行窗口. 有若干值得关注的选项, 已经用红色方框标出:
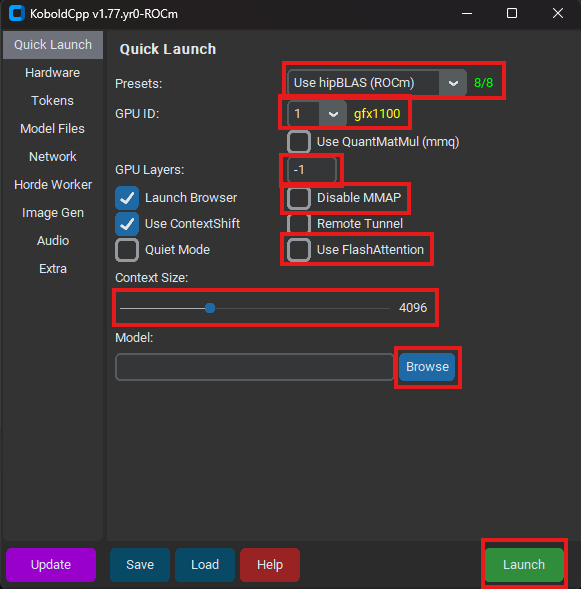
此时 koboldcpp 窗口应该处在 Quick Launch 界面, 你在这个界面中进行配置即可方便地加载 GGUF 模型. 让我们一项一项来看:
- Presets: 选择一套预设的加载方案. 如果你有 NVIDIA 显卡, 则在这个下拉式菜单中选择 Use CuBLAS; 如果你有 AMD 显卡, 则选择 Use hipBLAS; 如果你没有显卡, 则选择 Use CPU
- GPU ID: 当你选择使用显卡加载时, 会出现这个选项. 选择你要使用的显卡的 ID (如1, 2, 3, 4, All). All 表示使用所有显卡. 当你正确地选择了显卡序号时, 旁边会有黄色的字表明你选择的显卡的型号
- GPU Layers: 当你使用显卡加载时, 会出现这个选项. 选择你要放到显卡中的模型层数. 模型层数的含义和计算参考上文 认识量化->GGUF 中的相关知识
- Use FlashAttention: 勾选这个选项时, 将启用 FlashAttention 功能, 它能提高模型的运行速度
- Disable MMAP: 是否将模型完全加载并保持在内存中. 一般地, 如果没有出现兼容性问题, 不要勾选这一项
- 当没有勾选这个功能时, MMAP 处于启用状态, 模型文件被部分加载进内存中(换言之, 你用到哪里就加载哪里). 如果内存不够, 就将一部分模型从内存中丢出去
- 当勾选这个功能时, MMAP 处于禁用状态, 模型文件被完全加载进内存中. 如果内存不够, 就会导致电脑死机
- Context Size: 模型的上下文长度. 一般可以设置为8192. 当你的显存有富余时可以尝试加大这个数值
- Model: 选择你要加载的模型. 点击右侧的
Browse按钮, 选择你下载的 GGUF 模型. 如果这个模型被分成了多块, 则选择第一块模型文件
当一切都配置好后, 点击界面右下角的 Launch 按钮, koboldcpp 将会加载模型, 你可以在命令行窗口中观察加载的细节. 当加载完成后, 你可以通过在 http://127.0.0.1:5001/api 上运行的API来访问模型
ollama
当且仅当你满足以下所有条件时, 推荐你使用 ollama:
- 你是小白
- 你知道如何打开命令行, 并且输入简单的命令
- 你不想上hf寻找模型, 只想体验官方发布的模型; 或者你不想花太多时间跟着教程走, 只想最快速地跑起来一个大模型玩一玩
ollama 提供了最简单的大模型加载方案, 但相应地, 想要在 ollama 上做自定义配置也是最麻烦的
首先安装 ollama:
- 如果你也在用 Arch Linux, 可以通过一行命令快速安装 ollama:
- 如果你是N卡用户:
sudo pacman -S ollama-cuda - 如果你是A卡用户:
sudo pacman -S ollama-rocm - 如果你不想用显卡加载大模型:
sudo pacman -S ollama - 当你安装完成后, 通过这个命令来开启 ollama 服务:
sudo systemctl enable --now ollama
- 如果你是N卡用户:
- 如果你在使用 Windows, 则前往ollama下载页面下载 Windows 下的安装包, 然后依照指示进行安装
然后使用 ollama 下载模型:
- 你可以在ollama模型页面浏览可以下载的模型
- 当你找到你想要的模型后, 通过运行
ollama pull 模型名:标签来下载模型, 例如ollama pull qwen2.5:32b就会下载 Qwen2.5-32B 模型
此时你已经可以从 http://127.0.0.1:11434 这个由 ollama 提供的OpenAI兼容的API来访问你的模型了
或者你也可以在命令行中和模型对话, 通过运行: ollama run 模型名:标签 来启动, 例如 ollama run qwen2.5:32b
LMStudio
当且仅当你满足以下任一条件时, 推荐你使用 LMStudio:
- 你是小白
- 你在使用 MacOS
- 你想要用一些自己下载的模型, 但是 koboldcpp 那么多的可配置选项让你有些无所适从
- 你喜欢漂亮的软件界面
相较于koboldcpp, LMStudio的优势在于:
- 减少了需要配置的项目
- 提供了应用内下载模型的功能: 在LMStudio内, 你可以直接搜索hf上的模型然后下载
- 应用内即可直接和大模型对话, 界面效果远强于koboldcpp
总的来说, LMStudio是相比koboldcpp和ollama更加新手友好的选择, 唯一让我不喜欢的地方是, 它是闭源的商业软件
要使用 LMStudio, 首先前往官方网站下载安装包, 然后按照指示安装. 当安装完成后, 你应该能看到 LMStudio 的应用程序.
本教程的软件截图来自 LMStudio 0.3.5 Linux 版, 和最新的软件界面可能有细微差别
初始时是英文界面, 需要你切换到中文:
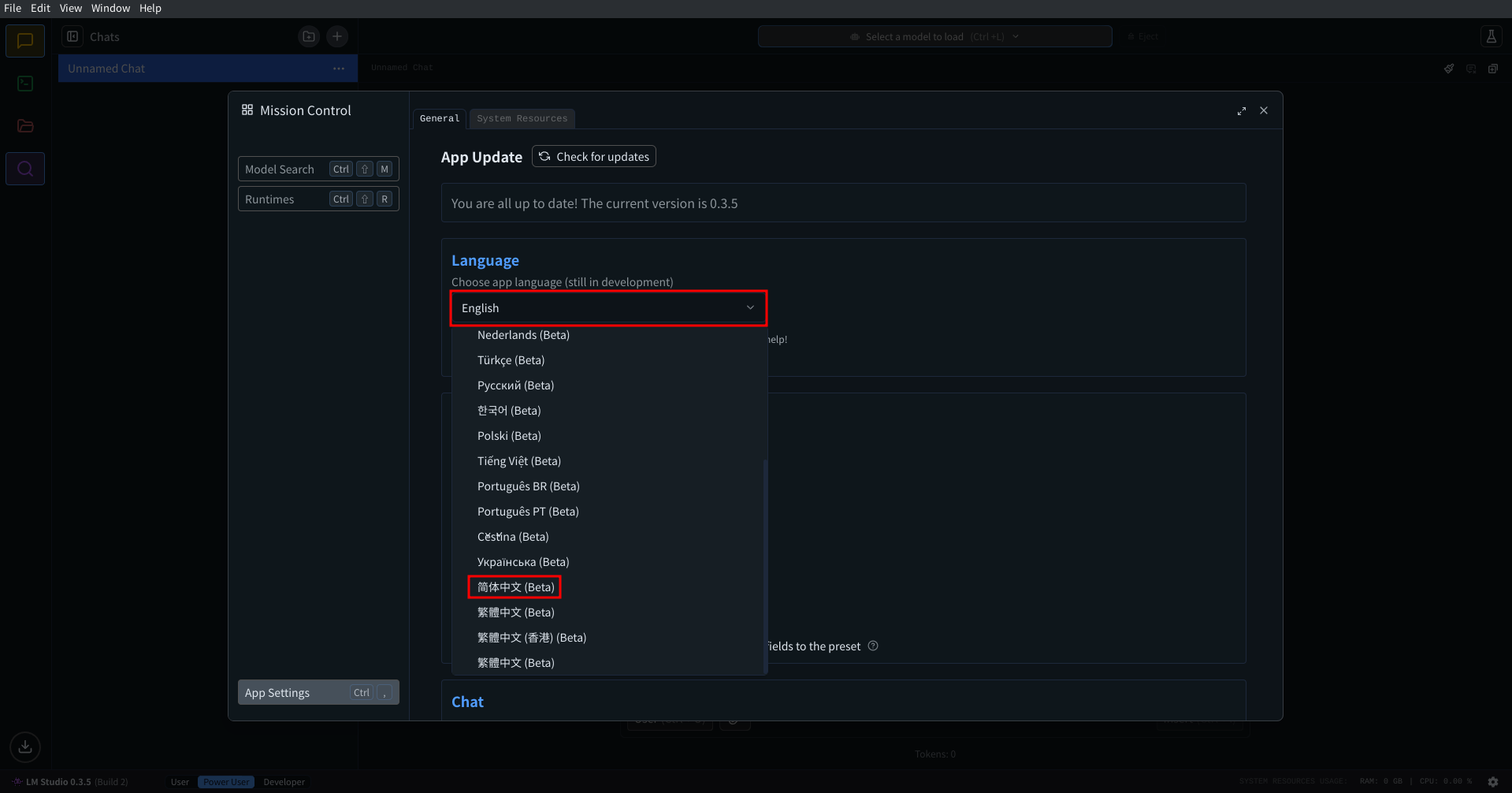
然后, 在 LMStudio 左侧选项卡内找到开发者一栏:
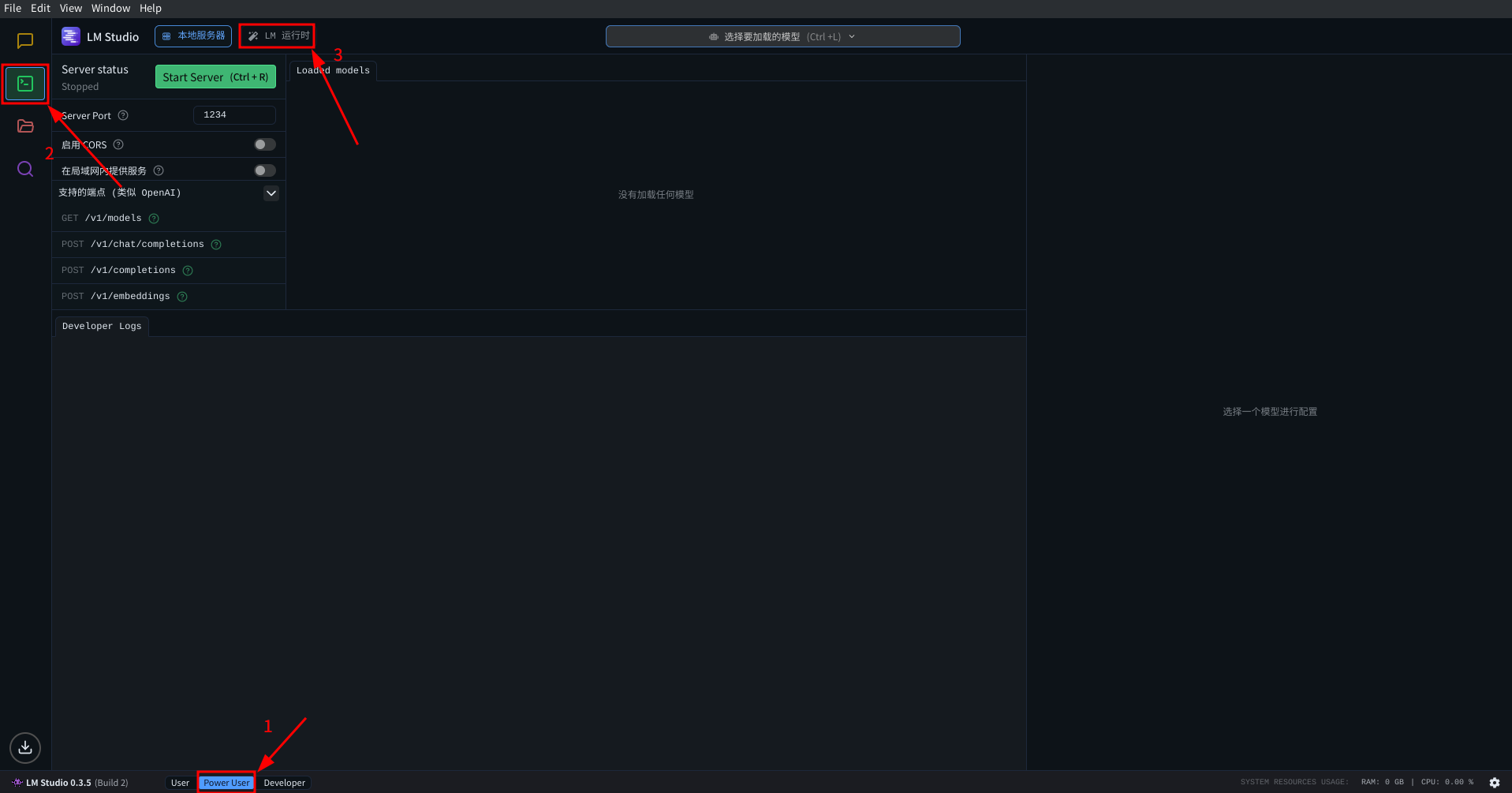
点击后在顶部左侧找到 LM运行时 按钮, 点击进入后端配置.
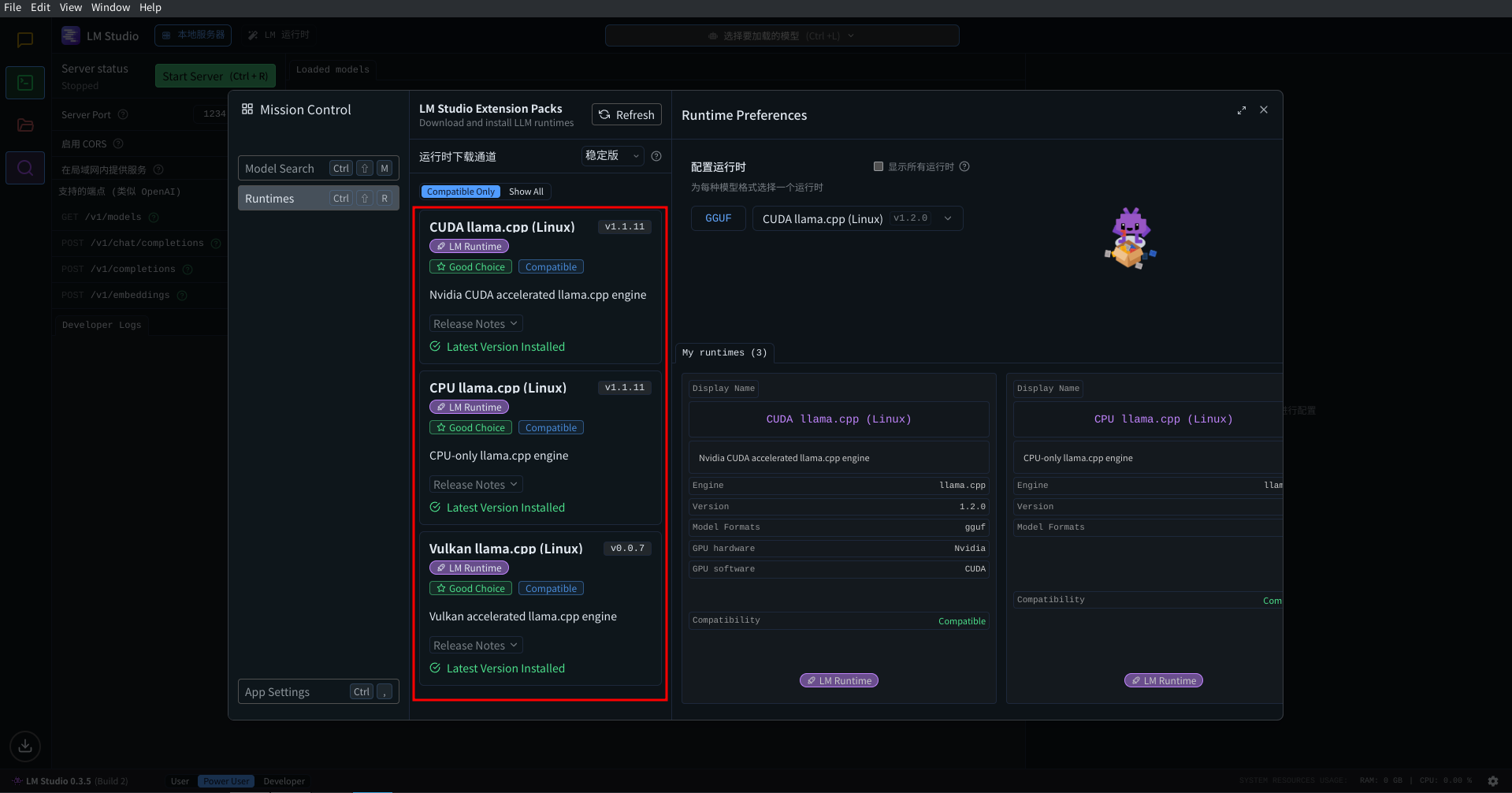
在这个页面中, 观察页面左侧的栏目, 根据你使用的显卡选择软件包下载:
- NVIDIA 显卡: 选择 CUDA llama.cpp (Windows)
- AMD 显卡: 选择 ROCm llama.cpp (Windows)
下载完运行时后, 在左侧选项卡内找到搜索一栏, 然后搜索你喜欢的模型进行下载. 注意这个过程需要你能流畅地访问HF
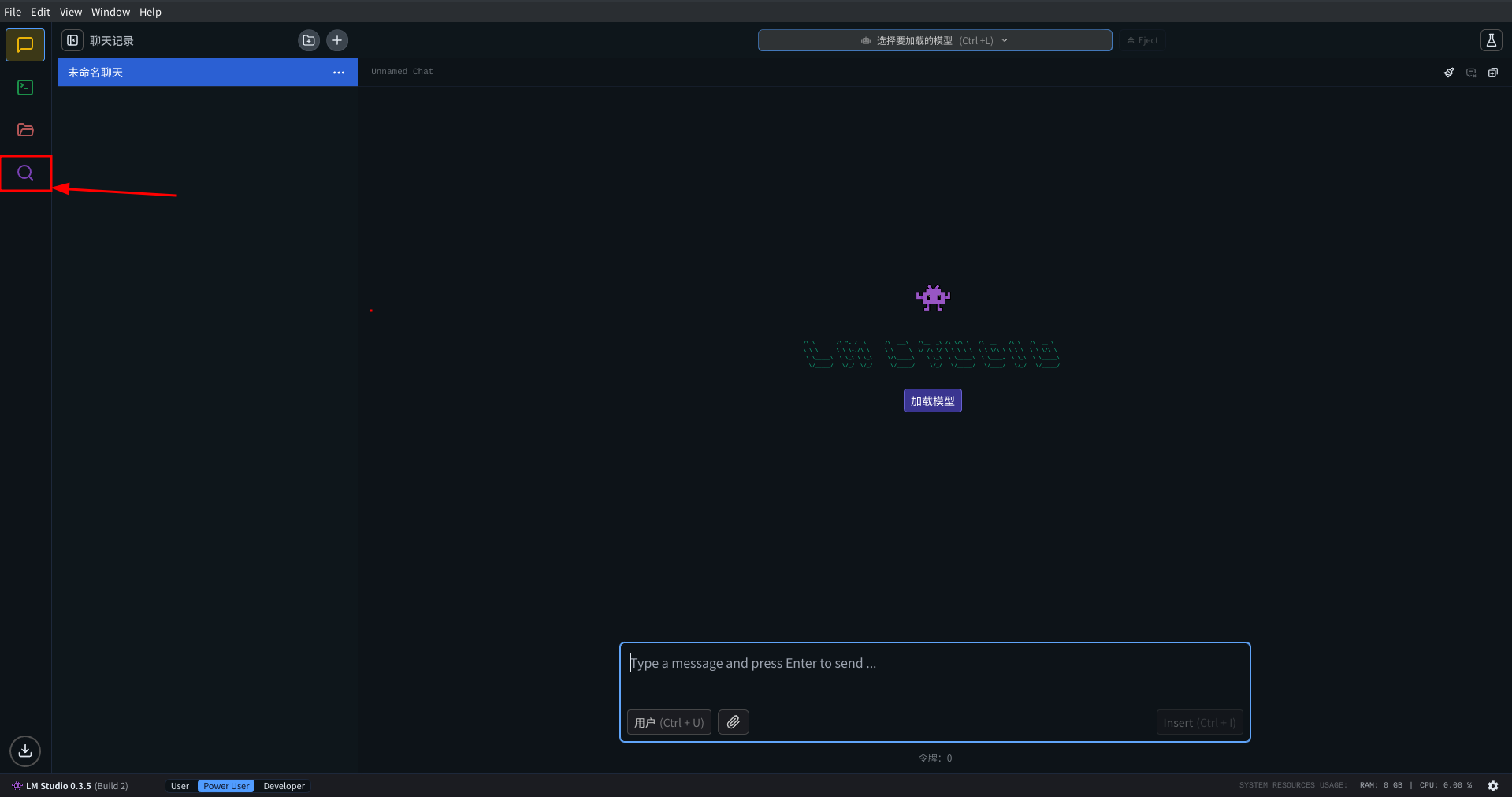
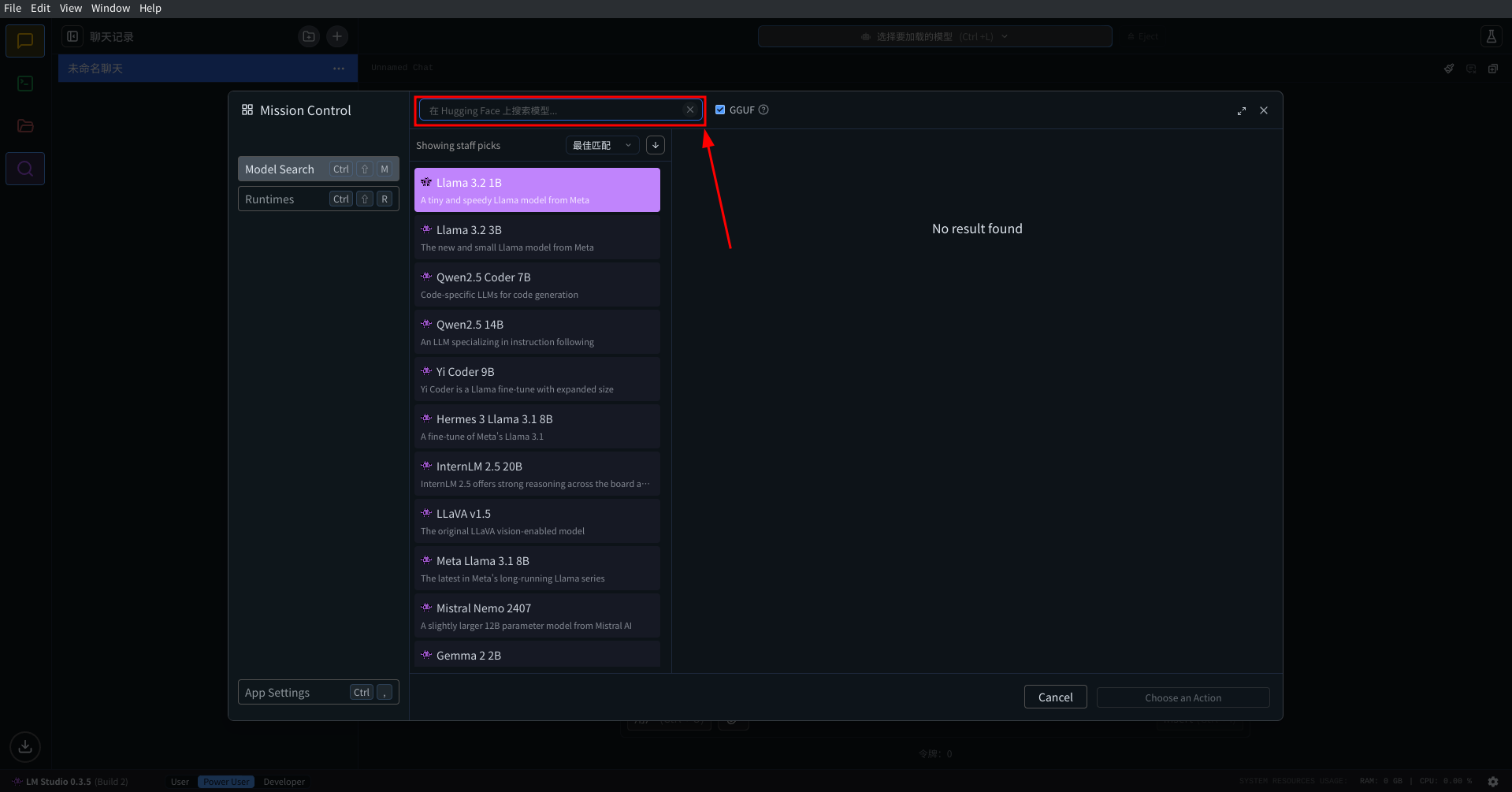
当你下载完成后, 在左侧选项卡内找到聊天一栏, 然后载页面最上方找到 选择要加载的模型 按钮, 在出现的下拉选项卡中点击你下载的模型, 然后点击加载模型, 等待模型加载完成. 然后你就可以在 LMStudio 内和模型对话了
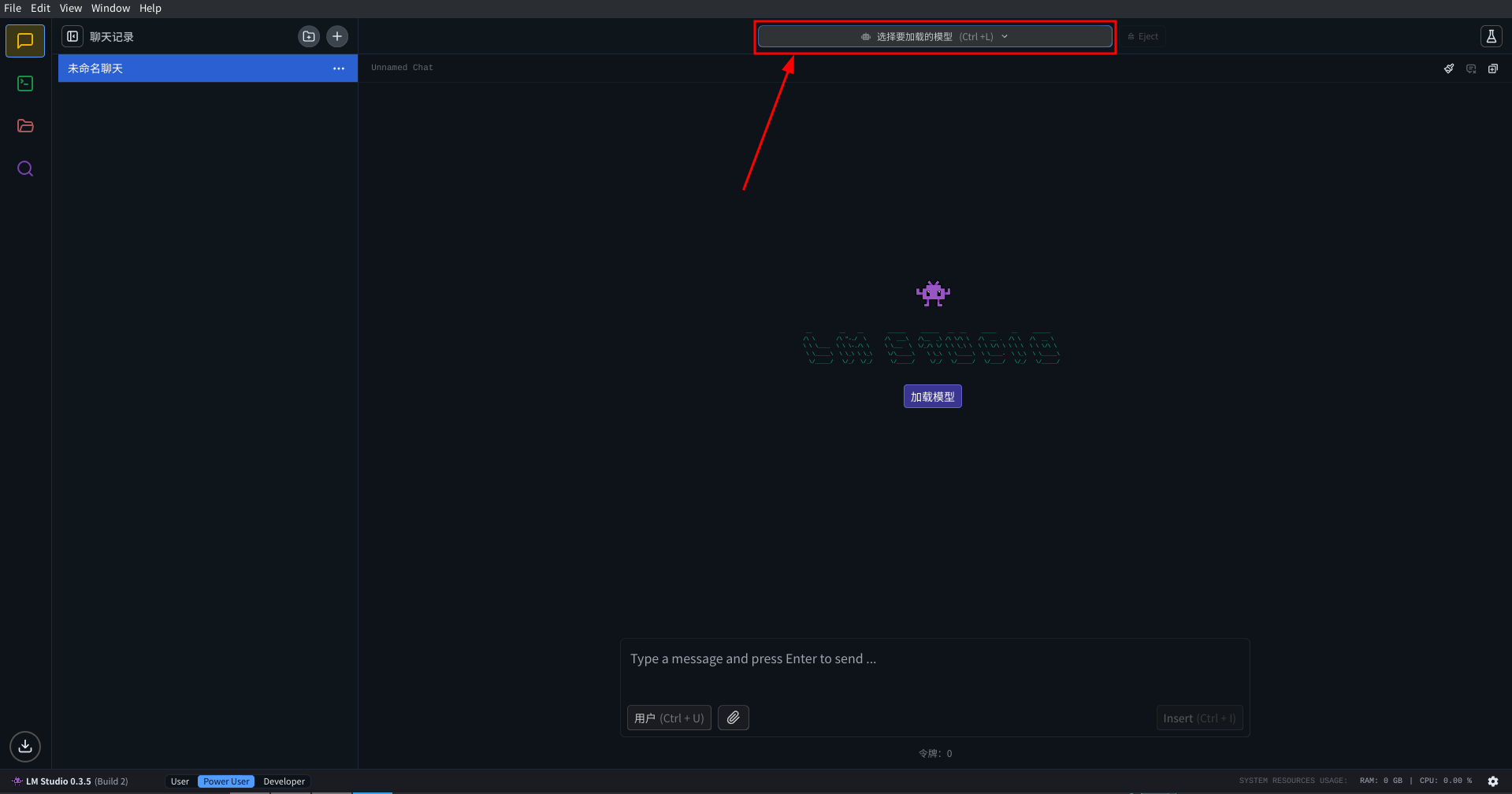
在你成功加载了模型之后, 你还可以启动 OpenAI 兼容的 API:
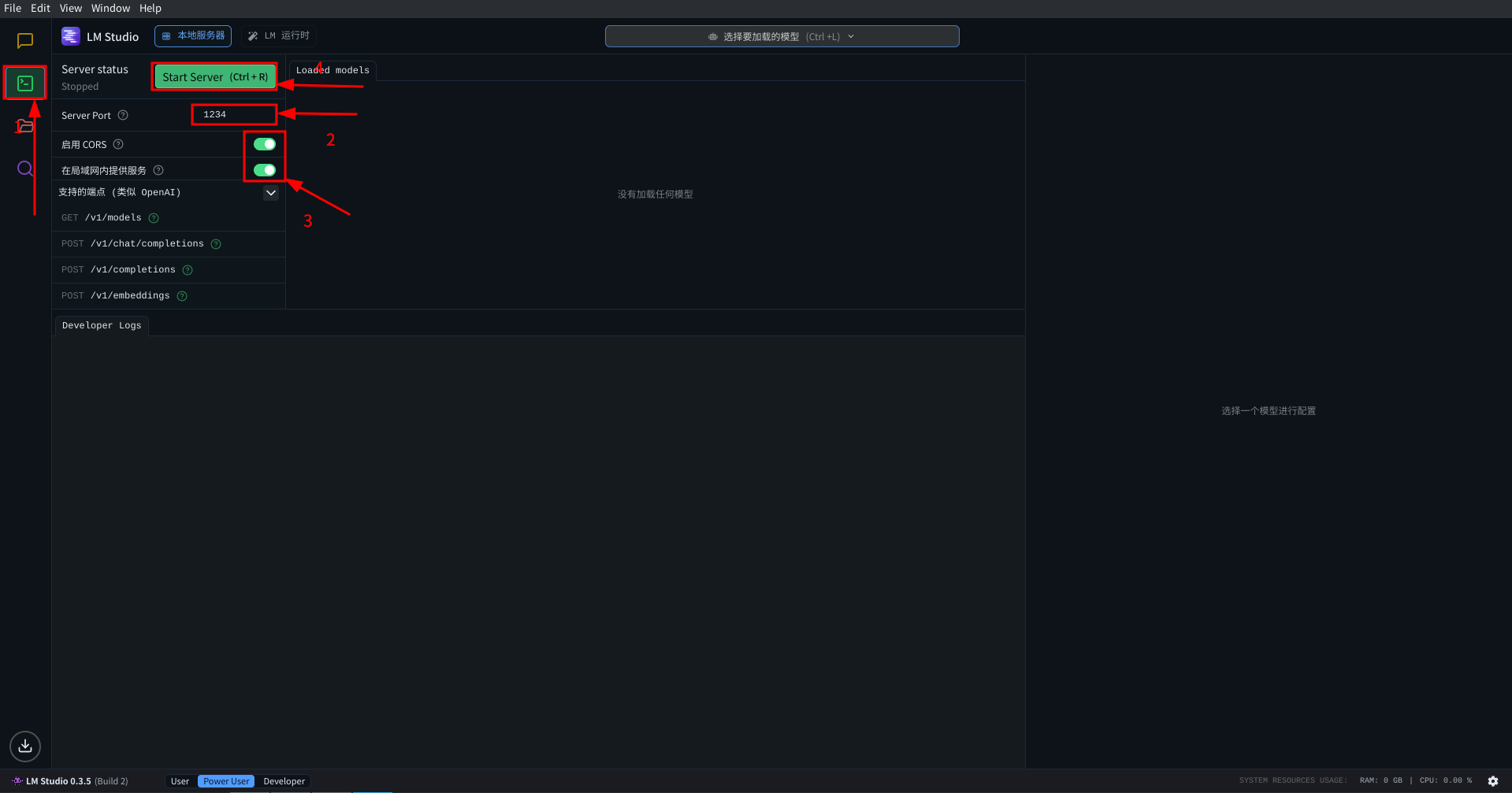
其中, 端口号 Server Port 可以任意选择, 例如图中保持的是默认的端口号 1234, 则 API 地址是 http://127.0.0.1:1234 注意开启 启用 CORS 和 在局域网内提供服务 选项以便进行更多的操作
llama.cpp
当你满足以下所有条件时, 推荐使用 llama.cpp:
- 你了解如何编译一个项目
- 你能读懂英语并且遵守文档给出的操作
- 你在使用 Linux
- 你想要得到使用 GGUF 能达到的最高性能
llama.cpp 的官方文档在这, 我就不多写了. 都用这个了, 想必不是小白了
tabbyAPI
别称: tabby
当且仅当你满足以下所有条件时, 推荐你使用 tabbyAPI:
- 你使用 Linux, 或者 WSL
- 你能读懂英语
- 你能阅读配置文件, 并能根据英语注释修改其中的一些项目
- 你能够使用命令行完成安装依赖, 启动项目等操作
- 你选择使用 EXL2 量化的模型
首先使用git克隆仓库到本地:
| |
然后安装依赖:
- N卡用户, 且cuda版本是12.几:
pip install ".[cu121]" - N卡用户, 且cuda版本是11.几:
pip install ".[cu118]" - A卡用户:
pip install ".[rocm]"
请注意: 如果你的显卡是n卡3000系以下, 或者使用A卡的话, 需要在自动安装依赖后手动卸载flash_attn:
pip uninstall flash_attn
接着创建配置文件:
配置文件在config.yml中, 配置文件格式为yml. 一开始你需要将config_sample.yml复制一份成config.yml, 然后修改里面的配置.
要修改的配置有这些:
- host: tabbyAPI的监听地址, 默认是
0.0.0.0 - port: tabbyAPI的监听端口, 默认是
5000 - disable_auth: 看你要不要开启api key验证了, 如果要验证的话, 第一次运行后在同目录下会生成一个
api_tokens.yml文件, 你可以在里面自定义你的api kay - model_dir: 模型所在的文件夹, 注意这里不是模型文件对应的文件夹, 而是模型文件所在的父文件夹. 如果你的模型文件是
/path/to/models/qwen2-72b, 那么这里就应该是/path/to/models - model_name: 模型文件名, 这就是你模型文件夹的名称了. 沿用上一点的示例, 这里应该是
qwen2-72b - use_dummy_models: 是否使用 dummy 模型, 开的话会生成一个
gpt-3.5-turbo的模型名, 可以用来给openai app当兼容的后端 - use_as_default: 一个列表. 是否将某个设置作为加载模型时的默认设置. 当你更改下面的条目时, 需要将对应的配置名加入到这个列表中
- max_seq_len: 最大上下文长度, 默认是从模型中获取, 你可以根据自己的显存大小调整这个值
- cache_mode: kv cache模式, 推荐Q4, 最激进的量化, 也最省显存
- chunk_size: 一个chunk的大小, 决定了模型处理上下文的速度, 这个值越大, 模型处理上下文速度越快, 但是显存占用越大. 范围是512~4096. 建议就在4个经典值中选: 512, 1024, 2048, 4096, 其他的跟这4个值相比, 速度大差不差
最后启动项目:
运行python start.py即可自动安装全部依赖并且按照配置文件加载模型
之后就可以python main.py跳过依赖安装, 直接加载模型了
vllm
当且仅当你满足以下所有条件时, 推荐你使用 vllm:
- 你有多并发的请求
- 你使用 Linux, 或者 WSL
- 你能读懂英语
- 你能阅读官方文档, 哪怕文档非常长
- 你能够根据官方文档在命令行中输入你想要的命令行参数
首先按照官方文档安装 vllm
然后跟着vllm官方文档来启动OpenAI兼容的API吧, 太多了, 我写不动了
Aphrodite engine
别称: aph
曾经支持 EXL2 量化的模型, 但现在已经不支持了. 我把它视为 vllm 的下位替代. 我找不到你应该使用 Aphrodite engine 而不是 vllm 的理由
webui
全称: text-generation-webui; 别称: tgw, ooba
这个项目似乎经历了一次大重构, 整个 UI 都和原来不一样了. 但我还没尝试过, 持观望态度
常见问题速查
我能跑多大的模型?
在 huggingface 上找一个模型, 点开它的文件页面, 计算里面文件的总大小. 然后加上 1~2G, 就是这个模型大致的内存/显存占用了. 看看你自己电脑的内存/显存大小是否足够
模型无法加载怎么办?
检查你的模型量化类型是否和你使用的加载器匹配, 检查你下载的模型是否完整. 另, 如果你在用 text-generation-webui, 请将它删除并换用其它的加载器
酒馆无法安装?
检查你是否有命令行代理, 如果没有, 请配置好再安装酒馆. 通过以下命令快速检查你的命令行代理是否有效:
| |
如果有效, 你应该能在命令行看到一些输出信息, 否则这个命令行将会卡住, 没有什么反应
跑模型速度慢怎么办?
尝试更换更小的模型, 或者更低等级的量化. 尝试更换量化方式. 尝试购买更强大的电脑硬件
模型胡言乱语怎么办?
检查你的模型是否是 instruct 模型,检查是否正确地选择了 prompt 模板, 检查采样器参数是否正确设置, 检查显卡显存是否够用
酒馆无法连接加载器?
检查是否填写了正确的API地址. 通常API地址由你选择的加载器给定